Inf-- kafka 从入门到放弃
概述
工作中用到了kafka ,本篇博文整理一下学习到的kafka相关知识,内容多来自网上(主要是官网doc,个人博客),侵删。
kafka 是Linkedin 使用Scala
编写的一个开源的分布式消息系统,当时开发的初衷是为了解决网站活动流数据(比如网页浏览,点击,驻留时间等等)的数据转发处理。因为活动流数据是实时且流量比较大,可想而知kafka
的最大特点就是高吞吐率且容易扩展。
kafka 的设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
使用场景
从不同的角度出发,kafka的作用也不同。
- kafka作为一个消息系统,类比redis,rabbitmq等同类产品,
- kafka作为一个存储系统,因为进入kafak的消息都会被持久化所以可以作为一个存储系统,
- kafka作为一个流处理系统,对于流数据,可以在kafka里多次处理,多次流转。
相应的,kafka 的使用场景大致如下:
- 作为传统消息队列系统的替换。
- 做metric监控数据的收集处理。
- 做日志数据的收集处理。
- 流数据处理。
- 事件驱动架构的核心组件。
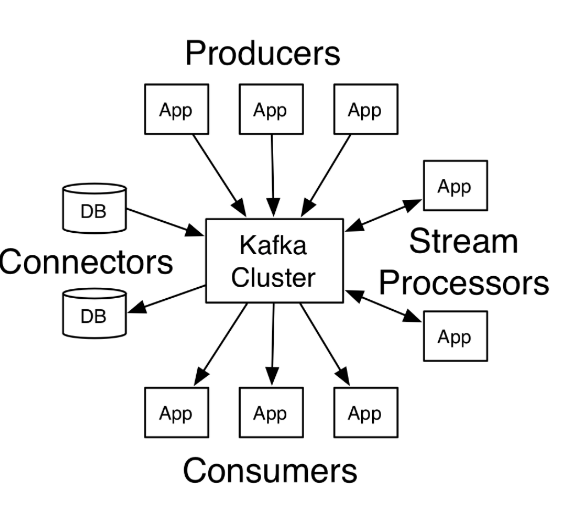
上图中可看出kafka的角色,相应的,kafka也提供了四种核心api:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
整体架构与术语
了解kafka,需要了解kafka 的一些术语,包括 producer,consumer,topic ,partition,broker等等。下面结合架构图统一解释:
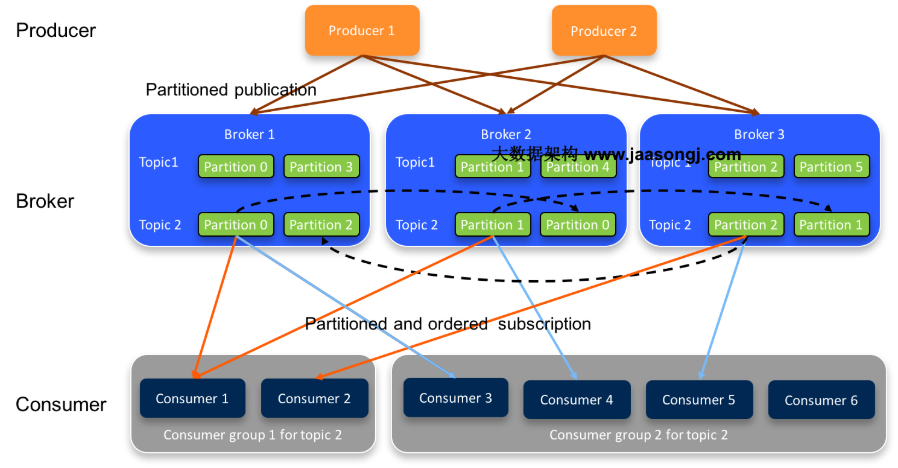
- 首先kafka 有producer 和consumer的概念,一个生产数据,一个消费数据,中间是一个broker(也就是一个消息队列),producer是以push的方式向broker推数据,consumer以pull 的方式从broker消费数据。
- producer 与consumer是通过topic 关联在一块的。topic类似于一个特定的分类。producer向某个指定的topic push数据,consumer从指定的topic消费数据。
- partition 的引入是为了解决并发量的问题,一个topic (至少有一个partition)可以有多个partition,多个partition并发的处理一个topic的消息。每一个partition以顺序不变的方式保存消息。
- broker 是kafka集群中维护发布消息的系统。每个broker针对每个topic可能包含0个或多个该topic的分区。假设,一个topic拥有N个分区,并且集群拥有N个broker,则每个broker会负责一个分区。 假设,一个topic拥有N个分区,并且集群拥有N+M个broker,则前N个broker每个处理一个分区,剩余的M个broker则不会处理任何分区 。 假设,一个topic拥有N个分区,并且集群拥有M个broker(M < N),则这些分区会在所有的broker中进行均匀分配。每个broker可能会处理一个或多个分区。这种场景不推荐使用,因为会导致热点问题和负载不均衡问题。
- Replicas of partition 分区副本仅仅是分区的备份,不会对副本分区进行读写操作,只是用来防止数据丢失。上图中topic2 就设置了 partition=2,副本会均衡地分布在broker中。
- consumer group: 一个consumergroup 里面会有若干个consumer实例,对应一个topic,这几个consumer实例都会消费该topic 中的消息,如果consumer实例的数量等于对应topic的partition数量,那么一个consumer对应一个partition(推荐)。如果consumer实例的数量小于对应topic的partition数量,那么一个consumer可能对应多个partition。如果consumer实例的数量大于对应topic的partition数量,那么多出的consumer不会参与到topic的消息消费。
安装与使用
原理
- kafka 依赖zookeeper来实现负载均衡以及原数据的存取。
- kafka之所以实现如此快的数据持久化,是因为磁盘io是顺序读写,在某些情况下,顺序磁盘访问能够比随即内存访问还要快(跟操作系统的预读,后写等技术有关)。
- kafka 的consumer group 实现了consumer 的auto rebalance,之前是依赖zookeeper实现的,会出现脑裂的情况,后来专门开发了coordinator组件来实现,目前仍在不断改进。
- kafka 的高性能有很多原因,包括消息的batch send,消息压缩(producer端和broker端都可做),ISR(in-sync replicas)机制,磁盘 append only,page cache等等。
参考文章
来源:https://zhangchenchen.github.io/2018/06/03/kafka-intro/
评论